
TRON 54
monografia RL
TRaceON - 54/ 19 febbraio 2024
di Adriano Parracciani aka cyberparra

Questo è un numero particolare di TRON, è il primo numero monografico indovinate su cosa? Come “dice” Jules Winnfield a Vincent Vega (nel meme), ovviamente sul Reinforcement Learning, che a seguire chiamerò RL.
Per RL s’intende un sottoinsieme del Machine Learning, quindi uno specifico approccio all’apprendimento automatico di una “macchina”.
Argomenti
🔔 RL novità del terzo millennio?
⚗️ RL in sintesi
🧱 RL spiegato con il gioco del muro
📈 DeepMind RiLancia
🟠 RLHF (dritto)
⚫ RLHF (rovescio)
🗂️ RL Casi d’uso
🎭RL potenzialità e rischi
💣 RL Fine di Mondo?
🙋 Ipse Dixit Luciano Floridi
RL novità del terzo millennio?
No! In realtà dobbiamo tornare indietro al 1989 quando uno studente di dottorato a Cambridge, Christopher Watkins, sviluppa “Q-learning“, il primo algoritmo di apprendimento per rinforzo. Prima delle reti neurali.
Fatto questo piccolo inciso, ora possiamo andare avanti.
RL in sintesi
🏋️♀️
Partirei dal termine reinforcement; apprendimento rinforzato si, ma da cosa?
Risposta bereve: dalle ricompense (rewards), attraverso le quali impara da sola senza bisogno di dati etichettati (supervised learning), ne dell’intervento umano.
Dettaglio: nel RL il programma di apprendimento automatico è un agente che compie delle azioni in un ambiente, da cui riceve il suo stato, cercando di massimizzare la ricompensa.
In sostanza:
l'agente esplora l'ambiente,
riceve uno stato della situazione,
prende decisioni,
riceve feedback in forma di ricompense o punizioni,
apprende di conseguenza come massimizzare la ricompensa nel tempo.
RL spiegato con il gioco del muro
Vediamo meglio come funziona, partendo da un progetto presentato nel 2013 da DeepMind1, e rappresentato dalla immagine qui sotto.
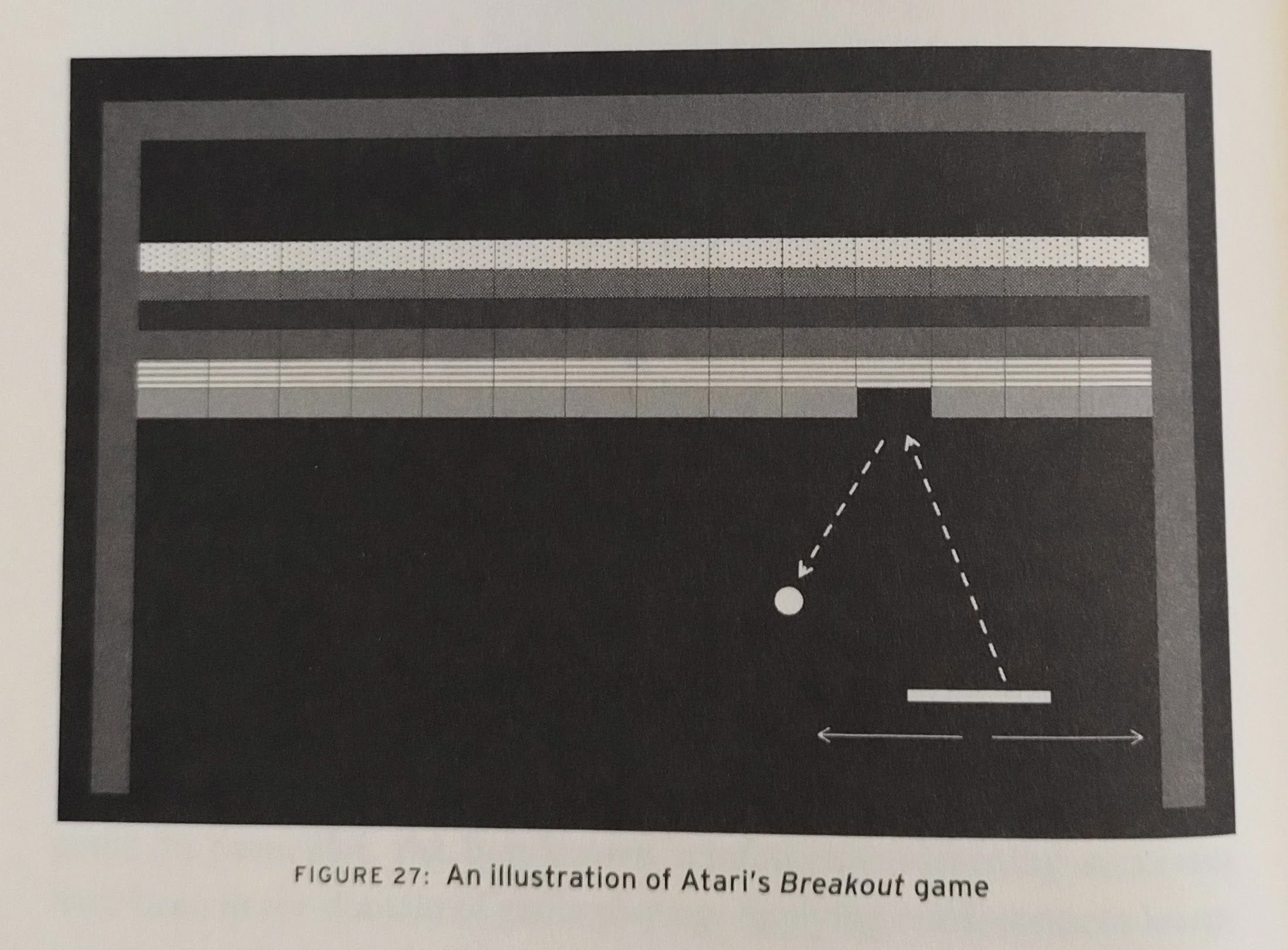
Credo che conosciate il gioco del muro, breakout2, dove bisogna abbattere i mattoni facendo rimbalzare la palla sulla paletta (paddle) in modo che li colpisca.
DeepMind utilizzò l’algoritmo Deep Q-Learning (RL) per far apprendere ad un computer come giocare autonomamente i giochi arcade sviluppati da Atari, tra cui breakout.
l’Ambiente all’inizio è una tabula rasa, e l’Agente non conosce le regole del gioco, ne come si gioca ne come si vince L’unica Azione che può fare l’agente è muovere la paletta sull’asse orizzontale.
La pallina parte, l’Agente riceve lo Stato della situazione dall’Ambiente e prende la decisione di muovere la paletta in modo casuale; la palla cade nel vuoto, e l’agente riceve una punizione. 👎Ogni volta che questo accade, il gioco termina (si chiama epoca nel processo di apprendimeto) e ne comincia un altro.
Nel corso di varie partite (epoche) l’agente muove di continuo la paletta in modo casuale fino a che colipisce la pallina ed ottiene un premio (reward).👍
A questo punto l’agente inizia ad apprendere per rinforzo ed il movimento totalmente casuale inizia a dominuire in favore di movimenti migliori appresi nelle partite precedenti.
Poi quando la palla rimbalza sulla paletta ed abbatte un mattone, il premio aumenta e l’agente apprende che quell’azione massimizza il premio e prosegue. 👍👍
Dopo 400 partite l’agente ha imparato a colpire sempre la palla che non cade più nel vuoto. La cosa che stupì i ricercatori accadde però dopo 600 partite: l’agente aveva imparato da solo a scovare la strategia del tunnel, illustrata qui sotto.
Incredibilmente e senza che i ricercatori potessero capire come, l’agente non solo aveva imparato da zero e senza il contributo umano a giorcare; ma aveva anche trovato la tecnica del tunnel, con il quale abbattere il maggior numero di mattoni con una sola mossa e nel tempo minore possibile.
Da quel momento l’agente era in grado di vincere sempre e battere qualsiasi giocatore umano.
DeepMind RiLancia
1️⃣ Nel 2015 DeepMind, ormai di proprietà Google, lancia AlphaGo, un programma che utilizza RL per imparare a giocare a Go. Due anni dopo AlphaGo sconfigge 4 a 1 il campione del mondo Lee Se-dol, un fatto che prima di allora non si credeva possibile.
AlphaGo ha appreso il gioco giocando da sola milioni di partite, reti neurali contro se stesse, diventando ogni volta sempre più forte attraverso il RL, scoprendo nuove strategie ed imparando dagli errori.
2️⃣ Negli stessi anni esce AlphaZero una “macchina” in grado di giocare a Scacchi, Go e Shogi notevolmente più potente della precedente. Anche in questo caso la rete neurale di AlphaZero è stata addestrata unicamente giocando da sola atraverso il RL
3️⃣ Lo scorso anno è uscita la versione AlphaZero with Diversity Bonus (AZdb) nella quale ci sono vari agenti AI_AlphaZero addestrati con stili di gioco diversi che propongono le loro mosse, ad una rete neurale che sceglie di volta in volta la migliore, quella che massimizza il punteggio durante la simulazione della sfida
link
4️⃣ Recentemente DeepMind ha utilizzato/sviluppato il Deep Reinforcement Learning (Deep RL) per addestrare due robot a sfidarsi nel gioco del calcio, imparando in modalittà trial&error le diverse competenze calcistiche: camminare, colpire la palla, rialzarsi da terra, segnare goal, difendersi
link
RLHF (dritto)
La sigla sta per Reinforcement Learning(from)Human Feedback; la differenza con RL risiede proprio nell’intervento umano (HF) che valuta direttamente le azioni effettuate dall’agente nelle varie epoche, attraverso un punteggio che si basa su qualità umane.
Verrebbe da pensare che quest’apporccio sia in contrasto con le capacità instriseche dei motori artificiali. Pensiamo infatti al caso degli scacchi o del Go di cui sopra, dove un suggerimento umano probabilmente non avrebbe garatito lo stesso successo.
Ci sono però scenari in cui l’agente è chiamato a valutare cose generiche, poco definite o astratte. È chiaro, ad esempio, che implementare un algoritmo per definire in termini matematici "divertente” o “umore” sia probabilmente impossibile o comunque notevolmente complesso. Mentre un umano ha non ha grandi difficoltà (pare) a valutare una battuta, od un’emozione.
Di fronte ad una frase del tipo: "un uomo entra in un caffè: splash", un LLM potrebbe metterci un po’ a capire che si tratta di una battuta, mentre un umano lo capisce subito (tranne quelli a cui devi spiegare anche le battute e le barzellette più semplici).
Nel RLHF, il riscontro umano HF si integra nell’addestramento dell’agente, e questo comporterebbe due vantaggi:
Agente apprende in un tempo minore sotto la guida umana
Apprendimento risulta più umano.
Per la ragione nel punto due, il RLHF è utilizzato ormai in gran parte nell’addestramento di LLM, per migliorarne l’accuratezza e gli aspetti etici.
RLHF (rovescio)
Qualcuno però fa notare il rovescio della medaglia criticando quest’apprroccio con il rischio di LLM moralisti, omologati, sottoposti ad una ideologia dominante, in questo caso quella woke. (leggi qui )
Qualcosa che abbiamo iniziato a vedere nei social quando pubblicando immagini di famose immagini di statue raffiguranti corpi nudi, il sistema di moderazione artificiale ti ammoniva per materiale inappropriato, secondo la legge del social stesso.
RL Casi d’uso
paragrafo curato con il supporto di ChatGPTControllo del bilanciamento dei veicoli autonomi: Le compagnie automobilistiche come Tesla e Waymo utilizzano il Reinforcement Learning per addestrare algoritmi di controllo che gestiscono in modo sicuro e efficiente il bilanciamento dei veicoli autonomi in una varietà di situazioni stradali.
Sistemi di trading finanziario: Le società di investimento e i trader utilizzano il Reinforcement Learning per sviluppare algoritmi di trading automatizzato che analizzano i dati di mercato in tempo reale e prendono decisioni di trading per massimizzare i rendimenti e ridurre i rischi.
Controllo del processo di refrigerazione: Le industrie alimentari e farmaceutiche utilizzano il Reinforcement Learning per ottimizzare i processi di refrigerazione e conservazione dei prodotti, garantendo che vengano mantenute condizioni ottimali di temperatura e umidità per la sicurezza e la qualità del prodotto.
Gestione dei data center: Le grandi aziende tecnologiche utilizzano il Reinforcement Learning per ottimizzare la gestione dell'energia e delle risorse nei loro data center, regolando dinamicamente la distribuzione dei carichi di lavoro e l'efficienza energetica per massimizzare le prestazioni e ridurre i costi operativi.
Controllo dei robot collaborativi: Le fabbriche moderne utilizzano il Reinforcement Learning per addestrare robot collaborativi che possono lavorare fianco a fianco con gli esseri umani in ambienti di produzione, imparando dai loro movimenti e adattandosi alle variazioni nell'ambiente di lavoro.
Ottimizzazione della pubblicità online: Le piattaforme di pubblicità online utilizzano il Reinforcement Learning per ottimizzare le strategie di offerta e di targeting degli annunci, massimizzando il ritorno sull'investimento per gli inserzionisti e migliorando l'esperienza degli utenti.
Gestione delle risorse idriche: Le autorità idriche utilizzano il Reinforcement Learning per ottimizzare la gestione delle risorse idriche, bilanciando la domanda e l'offerta di acqua tra utenti diversi e garantendo una distribuzione equa e sostenibile delle risorse idriche.
RL potenzialità e rischi
paragrafo curato con il supporto di ChatGPTPotenzialità del Reinforcement Learning:
Autonomia e Adattabilità: Gli agenti RL possono apprendere a compiere decisioni autonomamente in ambienti complessi senza richiedere istruzioni esplicite o supervisione umana continua.
Applicazioni in Domini Complessi: RL può essere utilizzato per risolvere problemi complessi in diversi settori, come robotica, giochi, finanza, automazione industriale, salute e molto altro ancora.
Ottimizzazione delle Prestazioni: Gli agenti RL possono essere addestrati per massimizzare determinati obiettivi, aiutando a ottimizzare processi, migliorare l'efficienza e ridurre i costi.
Esplorazione di Strategie Ottimali: RL permette di esplorare e scoprire strategie ottimali in ambienti in cui le regole e le dinamiche sono complesse o poco conosciute.
Rischi del Reinforcement Learning:
Comportamento Indesiderato: Gli agenti RL possono imparare comportamenti indesiderati o dannosi se il processo di addestramento non è ben progettato o se le ricompense sono specificate in modo errato.
Stabilità e Robustezza: Gli agenti RL possono non essere robusti rispetto a variazioni nell'ambiente o in presenza di dati di addestramento rumorosi o incompleti, il che potrebbe compromettere le prestazioni nel mondo reale.
Etica e Sicurezza: L'uso di RL in applicazioni critiche può sollevare preoccupazioni etiche e di sicurezza, ad esempio, nel caso di veicoli autonomi o sistemi di raccomandazione che influenzano le decisioni degli utenti.
Bias e Fairness: Se i dati di addestramento contengono bias o discriminazioni, gli agenti RL possono perpetuare tali comportamenti indesiderati, aumentando il rischio di decisioni ingiuste o discriminanti.
Complessità dell'Addestramento: L'addestramento di agenti RL può richiedere molte risorse computazionali, tempo e dati di addestramento, rendendolo impraticabile o costoso in alcuni contesti.
In sintesi, mentre il reinforcement learning offre molte opportunità promettenti, è importante considerare attentamente i rischi associati e sviluppare metodologie e politiche adeguate per mitigarli.
RL Fine di Mondo?
Nel numero 3 di TRON parlai di un team di ricercatori che vedevano nel RL un rischio mortale. A loro dire il problema sta nel fatto che Agenti Autonomi possono o potrebbero intervenire nel determinare il proprio sistema di premiazione, sostenendo che probabilmente la AI distruggerà l'umanità se potrà intromettersi nei sistemi di ricompensa.
N°3: AI FIne di Mondo, Make Mark Happy & altro
TRON Tracce dai mondi RAM: Robotica, AI e Metaverso di Adriano Parracciani aka cyberparra N°3 - 16 ottobre 2022
Ipse Dixit (Luciano Floridi)
Nessuno Spartaco artificiale guiderà una rivolta digitale
Consiglio di Visione
📚 Consigli di lettura
📖 Etica dell’Intelligenza artificiale

📖 2099 - il mondo a fine secolo
Il team di Raakel sta costruendo una macchina che prevede il futuro, loro la chiamano la Pizia; per noi sarebbe una Intelligenza Artificiale, ma il team non ama particolarmente il termine. Il nome tecnico della Pizia è PSP, acronimo che racchiude l’essenza della macchina.

L’anno successivo sarà acquistata da Google
Atari aveva assegnato il progetto di sviluppo del gioco a Steve Jobs (quello) che però non aveva le competenze e chiese aiuto a Steve Wozniak (quello) che lo sviluppò nel 1976.